Veamos ahora el control de flexibilidad del modelo desde el punto de vista del aumento de la familia de funciones consideradas y no del número de variables involucradas.
12.1 Regresión polinómica
Consideremos un modelo lineal en una sola variable \(y_i = \beta_0 + \beta_1 x_i + \epsilon_i\), al pensar en aumentar la flexibilidad del modelo para abordar problemas más complejos, podemos pensar en agregar términos cuadráticos, cúbicos y polinómicos de alto grado:
Estos modelos pueden llamarse modelos cuadráticos, cúbicos; y en general: modelos polinómicos. Las ecuaciones son no lineales en \(x\) pero siguen siendo modelos lineales en los parámetros, por lo que se resuelven de la forma habitual usando cuadrados mínimos ordinarios (OLS)
Podemos agregar tantos términos al polinomio como sea necesario para obtener un modelo bastante flexible, pero este enfoque tiene muchos inconvenientes y suele evitarse en la práctica. Para ver por qué, hagamos algunas simulaciones.
12.1.1 Datos simulados
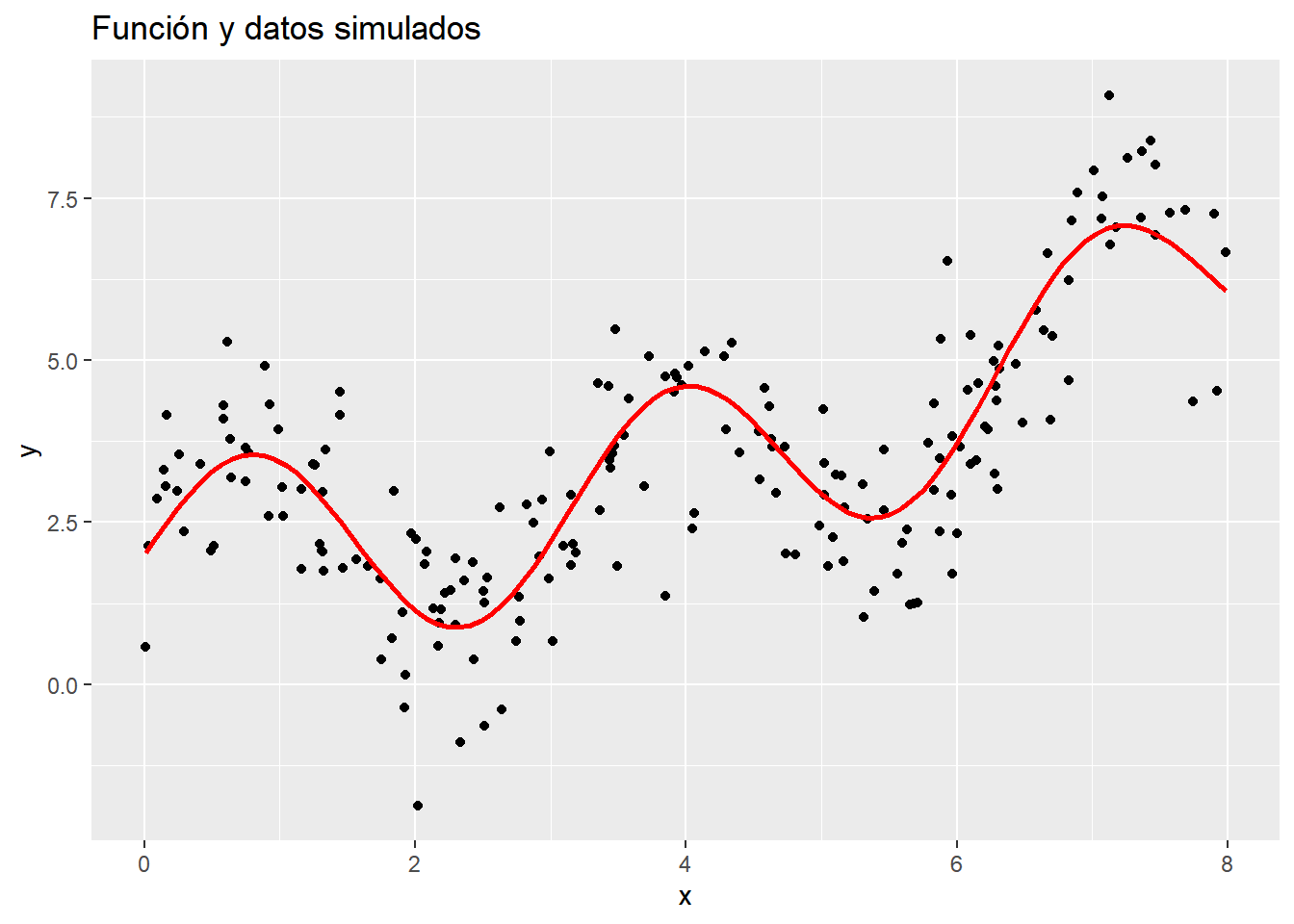
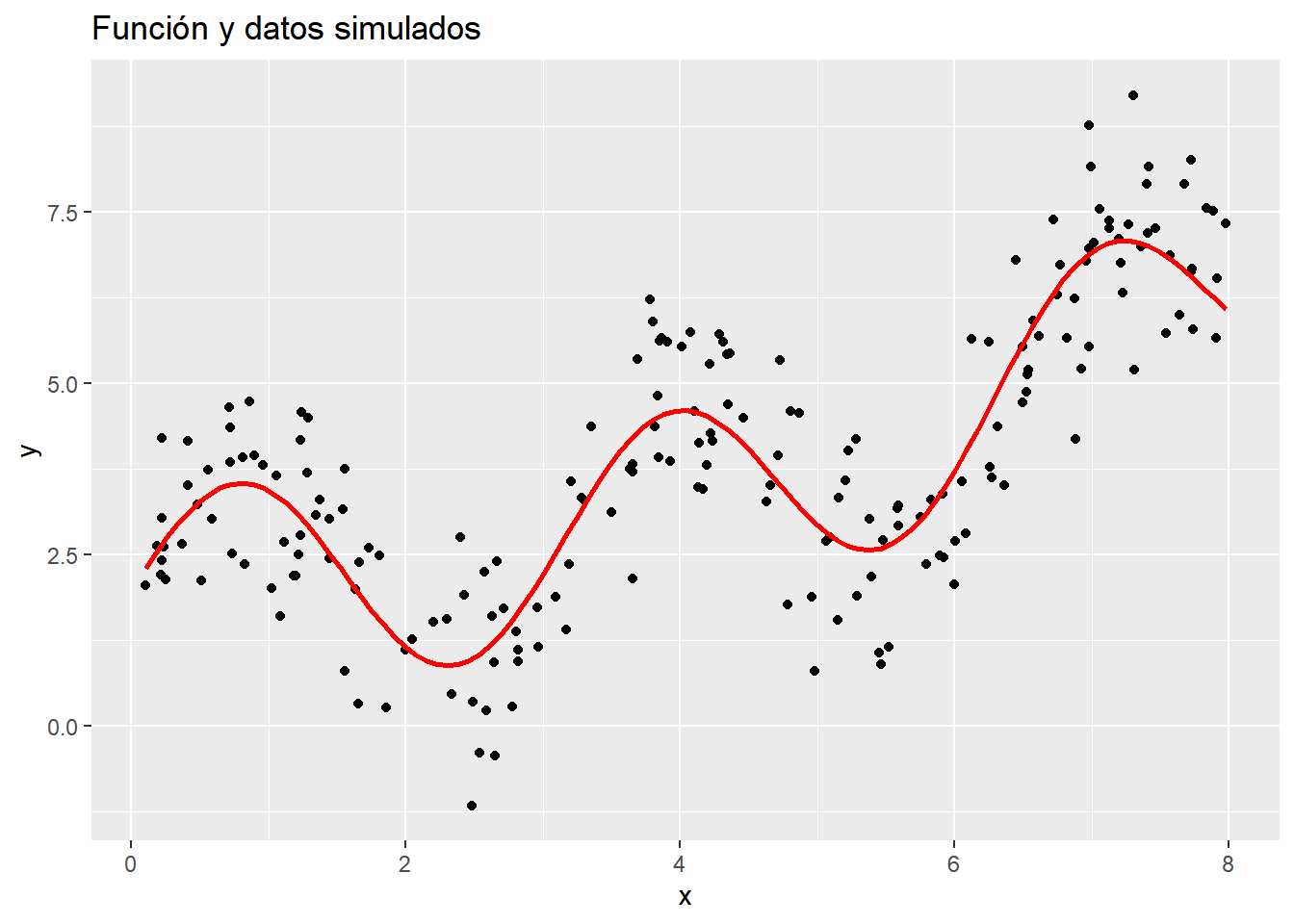
Consideremos la función
\[f(x)=2 + 1.5 \mathrm{sen}(2x) + 0.07x^2\]
Y un ruido aleatorio \(\varepsilon_i\) con una distribución normal estándar. Los datos se generan mediante la ecuación:
library(tidyverse)library(plotly)set.seed(789)n <-200f <-function(x) 2+1.5*sin(2*x) +0.07*x^2x <-runif(n, 0, 8)error =rnorm(n)y <-f(x) + errordatos <-tibble(y = y, x = x)plot1 <- datos |>ggplot(aes(x,y)) +geom_point() +geom_function(fun = f, colour ="red", linewidth =1) +labs(title ="Función y datos simulados")plot1
En la gráfica, podemos ver la función \(f(x)\) que debemos estimar a partir de los datos
12.1.2 Extrapolación
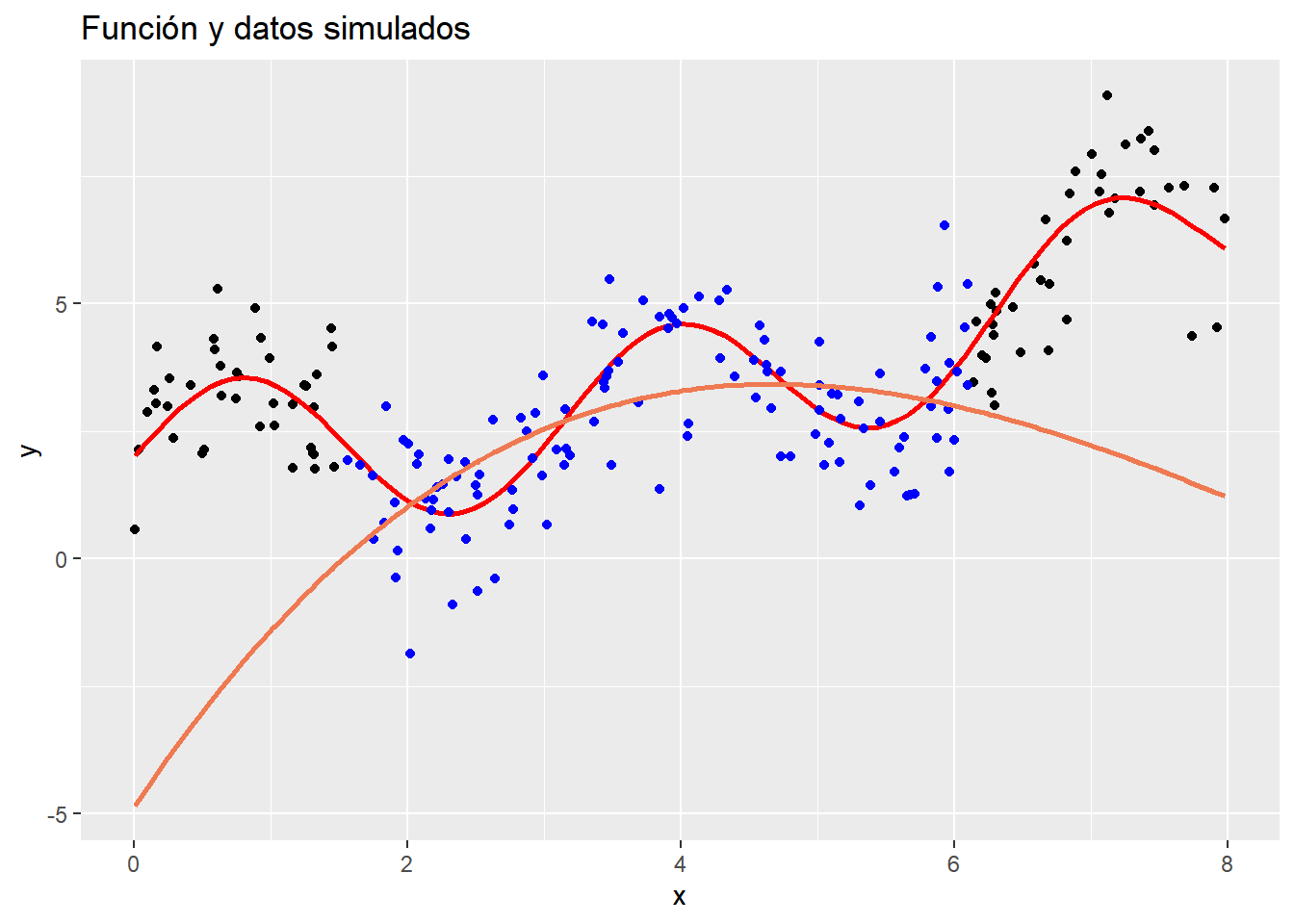
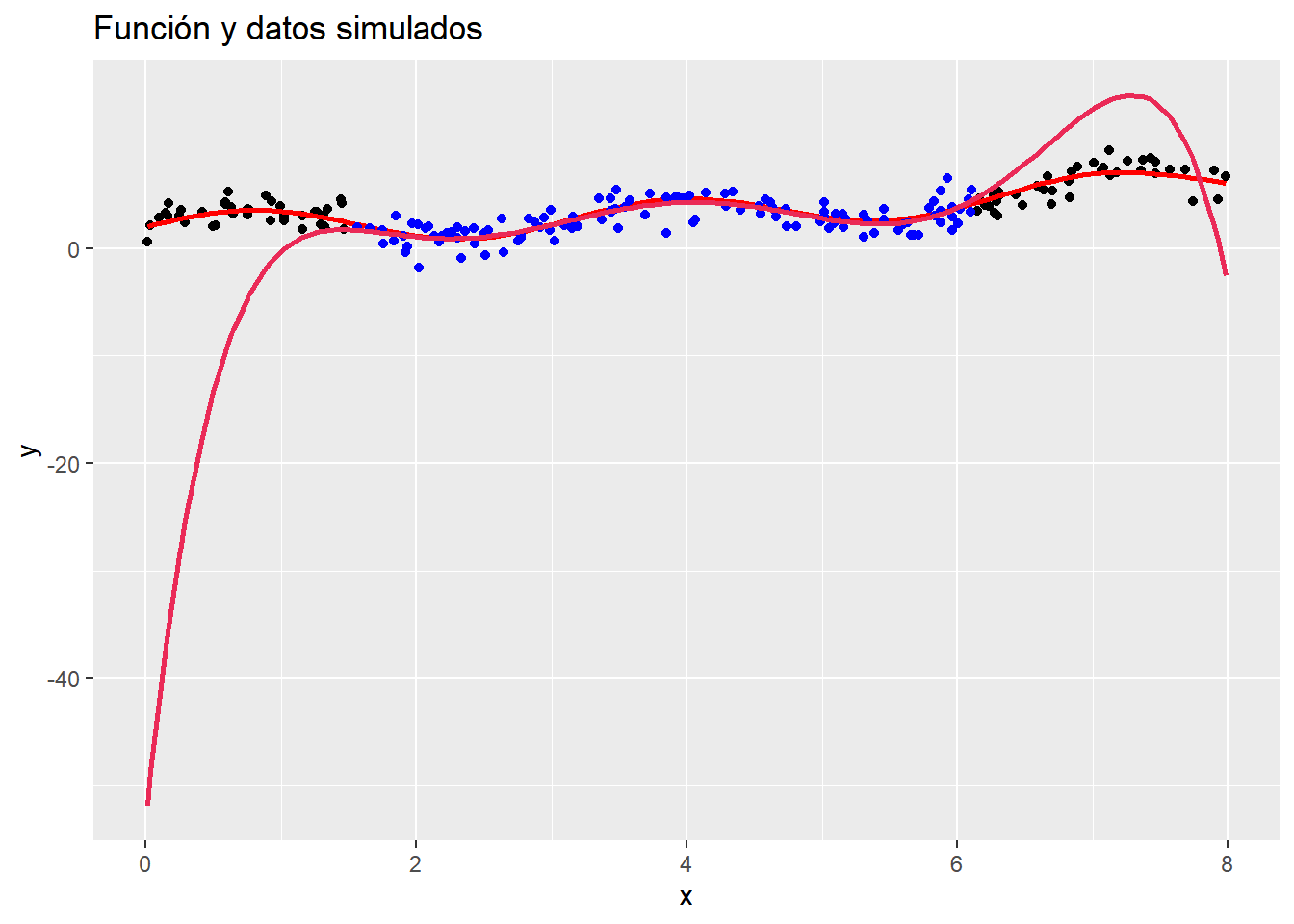
Vamos a resaltar primero, lo deficiente y poco recomendable que es usar regresión polinómica para extrapolar predicciones fuera del rango de valores observados (esto no solo es cierto para regresión polinómica sino para la mayoría de métodos). Para hacerlo, usemos solo la parte interna de los datos y miremos cómo se comporta más allá de este intervalo al ajustar polinomios de grados superiores. Para facilitar la tarea, usamos (entre otras cosas) la función poly para crear de forma rápida los valores de los polinomios requeridos para el ajuste. Veamos un pequeño ejemplo
Con esto, podemos ajustar modelos polinómicos de forma más sencilla
library(randomcoloR) # para generar colores de forma aleatorialibrary(patchwork)pg <-floor(n/5):floor(4*n/5)datos_sub <- datos |>arrange(x) |>slice(pg)plot2 <- plot1 +geom_point(data = datos_sub, mapping =aes(x, y),colour ="blue")for(i in3:6){ ajuste.lineal <-lm(y ~poly(x, i, raw = T),data = datos_sub) y_pred <-predict(ajuste.lineal, newdata = datos) plot3 <- plot2 +geom_line(aes(x=x, y=y_pred), size=1, colour =randomColor())print(plot3)}
Analice las gráficas y concluya al respecto.
12.1.3 Varianza de los modelos
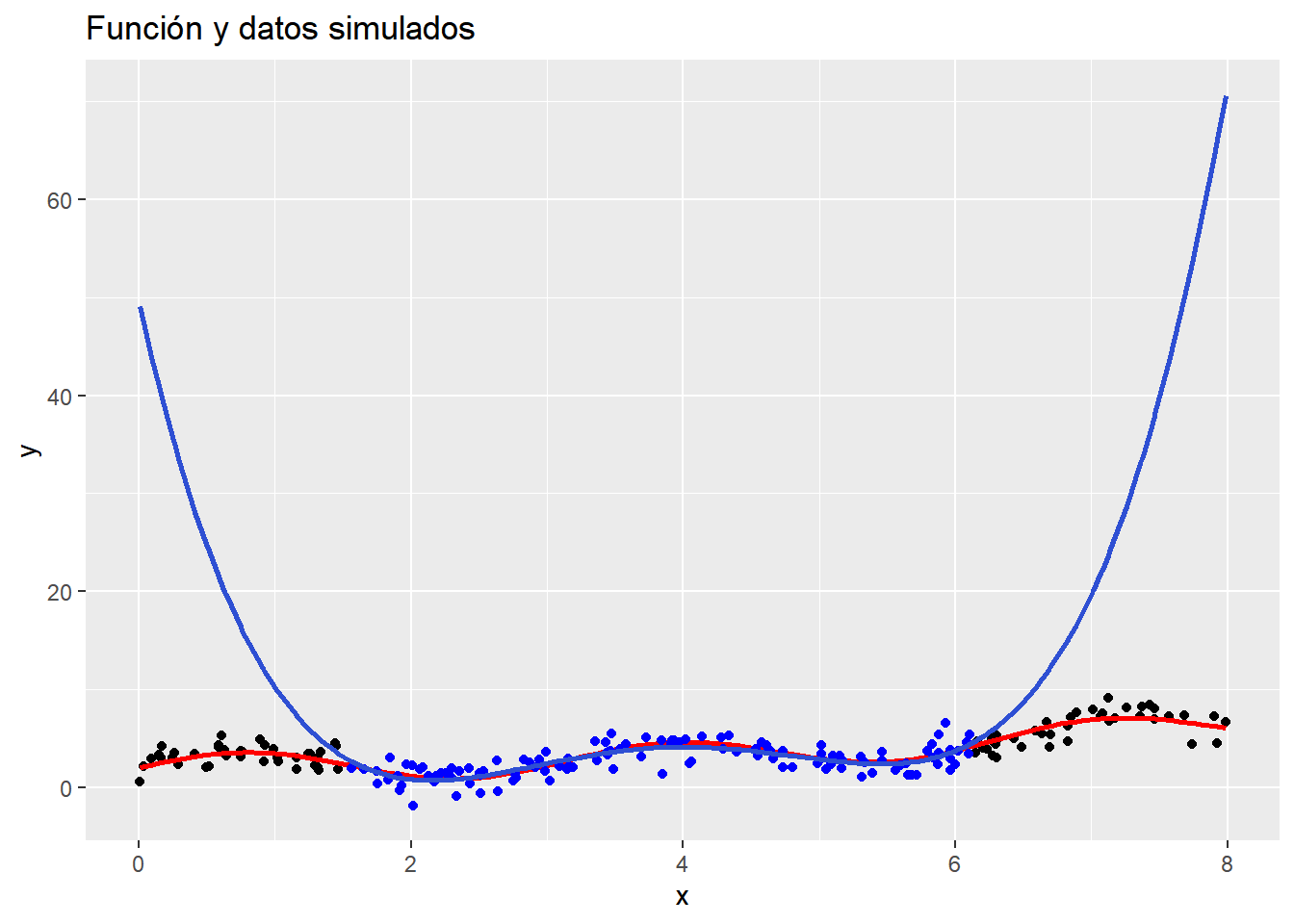
Podemos evaluar el desempeño de un polinomio de alto grado desde otro punto de vista: Cómo cambia la estimación al cambiar los datos
d <-20for(i in1:4){ x <-runif(n, 0, 8) error =rnorm(n) y <-f(x) + errorassign(paste0("data", i), tibble(x = x, y = y)) modelo.lineal <-lm(y ~poly(x, degree = d, raw = T))assign(paste0("y_pred",i), predict(modelo.lineal))}plot4 <-ggplot() +geom_function(fun = f, color ="red", linewidth =1) +geom_line(aes(x, y = y_pred1), data = data1,linewidth =0.8, color =randomColor()) +geom_line(aes(x, y = y_pred2), data = data2, linewidth =0.8, color =randomColor()) +geom_line(aes(x, y = y_pred3), data = data3, linewidth =0.8, color =randomColor()) +geom_line(aes(x, y = y_pred4), data = data4, linewidth =0.8, color =randomColor())# plot4ggplotly(plot4)
¿Qué puede decir sobre estos resultados?
12.2Regression Splines
Así que aumentar la flexibilidad del modelo a través del grado del polinomio no es el camino a seguir. En su lugar podemos ajustar varios modelos sencillos en subintervalos.
Este enfoque nos trae de vuelta a un problema expresado en bases funcionales (¿por qué se da eso? explique), donde debemos estimar unos parámetros lineales (entonces, ¿cuál es la ventaja de estos métodos?) para resolver el modelo.
Las bases dependerán del tipo de modelo ajustado y de la cantidad y posición de los nodos. Como el objetivo es facilitar la tarea, por lo común, los nodos o puntos de corte se ponen de forma uniforme en todo el intervalo (piense en qué situaciones podría ser ventajoso hacerlo de otra manera).1
1 Bono para quien deduzca las bases funcionales de un cubic spline (ver ejercicio 1 del cap 7 del libro guía)
La flexibilidad del modelo resultante se puede controlar de 2 formas:
Variando la complejidad del modelo ajustado en cada subintervalo.
Variando la cantidad de nodos.
Pero el lema es “Ajustar varios modelos sencillos”, entonces lo más recomendado (y lo que mejor funciona en la práctica) es variar la cantidad de nodos. Cuando estos modelos sencillos son polinomios de bajo grado y tienen ciertas restricciones en los puntos de corte (¿cuáles son esas restricciones o condiciones?) se obtienen los modelos conocidos como regression splines
12.2.1 Simulaciones
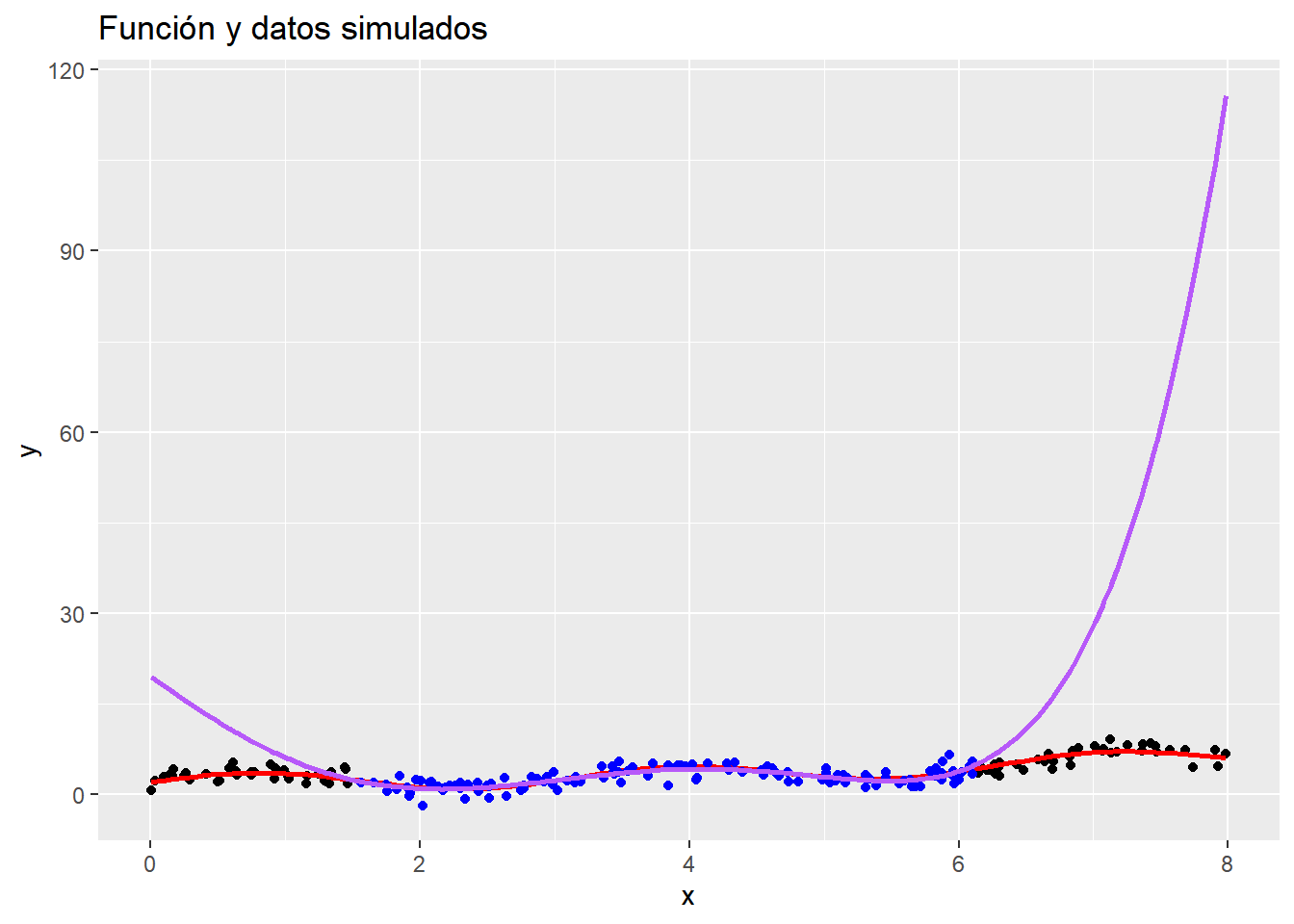
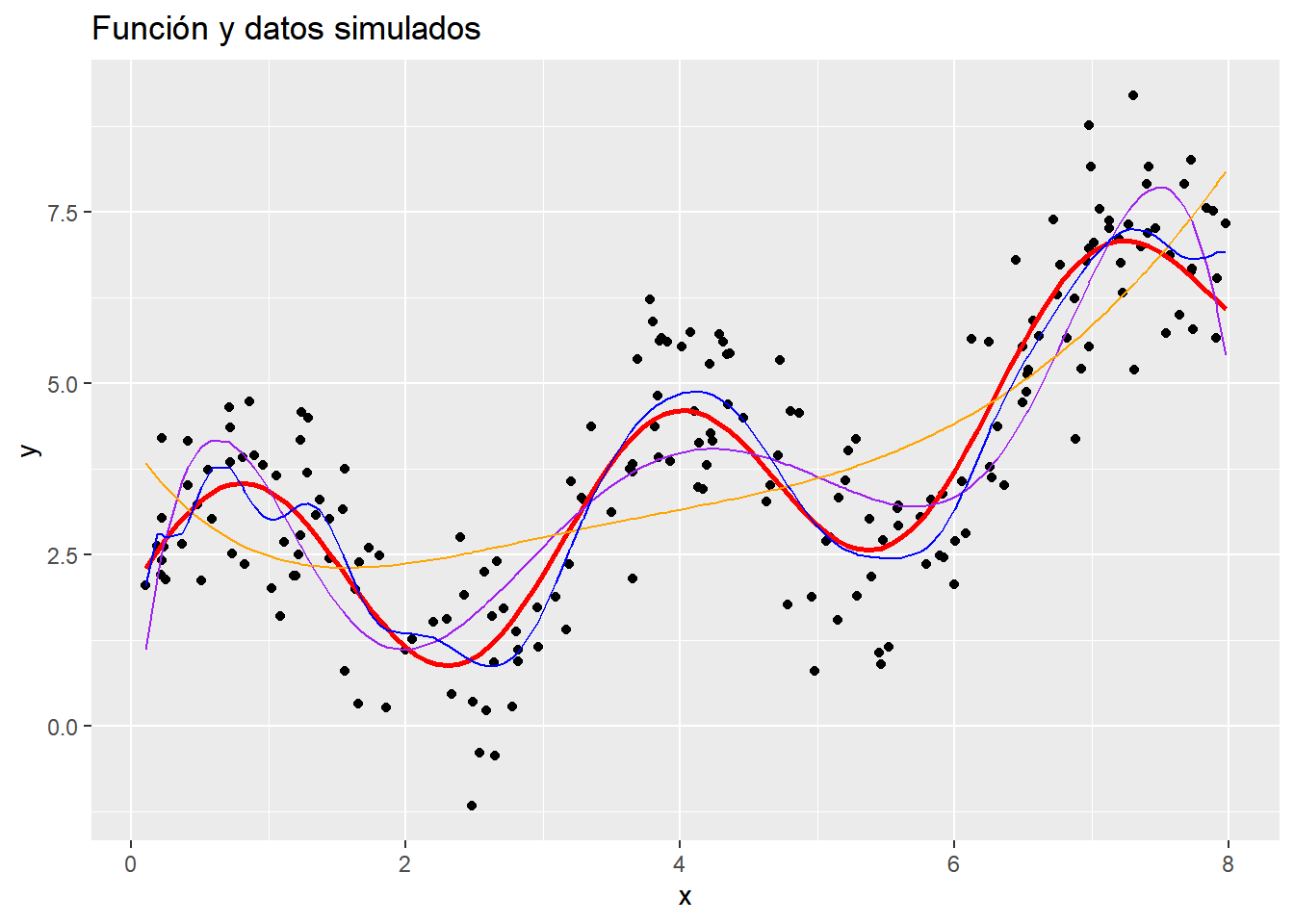
Veamos cómo resulta en las simulaciones. Para facilitar la tarea, usaremos el paquete splines en R
library(splines)x <-runif(n, 0, 8)error =rnorm(n)y <-f(x) + errordatos <-tibble(y = y, x = x)plot1 <- datos |>ggplot(aes(x,y)) +geom_point() +geom_function(fun = f, colour ="red", linewidth =1) +labs(title ="Función y datos simulados")plot1
d <-4# con 3 nodosnodos <-seq(0, 8, length.out =5)nodos <- nodos[-c(1,length(nodos))]d_spline <-lm(y ~bs(x, knots = nodos, degree = d))ds_pred1 <-predict(object = d_spline)# con 1 nodonodos <-seq(0, 8, length.out =3)nodos <- nodos[-c(1,length(nodos))]d_spline <-lm(y ~bs(x, knots = nodos, degree = d))ds_pred2 <-predict(object = d_spline)# con 20 nodosnodos <-seq(0, 8, length.out =22)nodos <- nodos[-c(1,length(nodos))]d_spline <-lm(y ~bs(x, knots = nodos, degree = d))ds_pred3 <-predict(object = d_spline)plot5 <- plot1 +geom_line(aes(x = x, y = ds_pred1), linewidth =0.5, color ="purple") +geom_line(aes(x = x, y = ds_pred2), linewidth =0.5, color ="orange") +geom_line(aes(x = x, y = ds_pred3), linewidth =0.5, color ="blue")plot5
ggplotly(plot5)
Ejercicio para la casa para reducir los niveles de cortisol
tomar un vector de cantidad de puntos de corte (nodos) y elegir el mejor valor con validación cruzada.